
Implicit Entity Networks (LOAD)
The LOAD document model
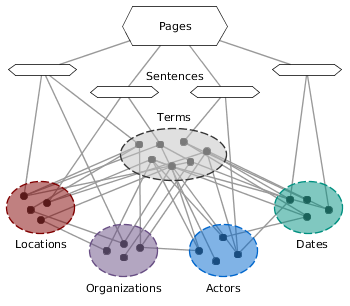
Real world events, such as historic incidents, typically contain both spatial and temporal aspects and involve a specicific group of persons. This is often reflected in the descriptions of events in textual sources, which contain mentions of named entities and dates. Given a large collection of documents such as news articles, however, such descriptions may be spread across multiple documents. LOAD is a graph-based model that supports browsing, extracting and summarizing real world events in such large collections of unstructured text based on named entities: Locations, Organizations, Actors and Dates. Similar to a knowledge base, the graph represents the implicit connections between related entities and assigns to them a strength based on the overall textual distances of the entities. Although the type of connection itself is not part of the model, the addition of terms, sentences and documents to the model allows its use as an index structure for the efficient retrieval of relevant instances of entity co-occurrences to support traditional methods of event extraction and analysis. Thus, the LOAD model not only enables near real-time retrieval of information from the underlying document collection, but also provides a comprehensive framework for browsing, exploring and summarizing event data. For further details, please refer to the original publication.
We recently added a browser-based online interface called EVELIN that can be used to browse LOAD networks of the English Wikipedia (EVELIN wiki) or a collection of English news articles from May 2016 to November 2016 (EVELIN news).
In the following, we provide a number of resources for the construction of a LOAD graph from document collections that are already annotated for named entities, as well as LOAD graphs for the text of the English Wikipedia.
LOAD graphs of the English Wikipedia
Here, we provide the LOAD graphs that we constructed from the English
Wikipedia (Wikipedia dumps of May 2016), based on annotations of named
entities in the unstructured text. We provide two versions of the graph,
derived from different schemes for annotating the named entities. The
first version is conceptually very similar to the originally published
version and uses for annotations the Stanford NER (persons, locations and organizations) and Heideltime
(dates) with no disambiguation. The second version is closer to a
knowledge base. While we still annotated dates with Heideltime, persons,
locations and organizations are annotated through Wikidata and
Wikipedia links, which creates a highly accurate result and includes
automatic disambiguation and entity linking to Wikidata.
Please note that the LOAD graphs are large.
For working with the in-memory representation we recommend using a
machine with at least 128 GB or memory. To support application scenarios
with available memory, we also include code for importing the LOAD
graphs in a MongoDB (see code linked below).
For
applications in NLP, we also provide the entire content for the sets of
sentences that appear as nodes in the LOAD graphs. Due to the size,
these are separate downloads. They are supplied in JSON format and can
thus easily be imported in a MongoDB or another database. Please be
aware that this is a large portion of the English Wikipedia content and
the respective licenses thus apply (i.e. creative commons).
Wikipedia LOAD graphs (Stanford NER + Heideltime)
This version is conceptually almost identical to the originally
published version of the LOAD network. It uses the unstructured text of
the entire English Wikipedia as input (dump of 2016-05-01). Named
entities were annotated with Stanford NER (persons, locations and
organizations) and Heideltime (dates). Dates were normalized but no
disambiguation was performed for the entities. In contrast to the
original LOAD graph, this version also includes set-internal edges (e.g.
between two persons or between two locations). For a brief overview of
the data format, please refer to the included file metaData.txt.
If you require a representation of the data as an edge list, please
refer to the code linked below, which can be used to import the graph in
a MongoDB.
[zip] Download LOAD graph annotated with Stanford NER and Heideltime (12.1 GB)
[zip] Download corresponding sentence content as a zip file (3.2 GB)
Wikipedia LOAD graphs (Wikidata + Heideltime)
This version of the LOAD graph was constructed from the unstructured text of the English Wikipedia (dump of 2016-05-01). Dates were annotated and normalized by Heideltime. All other named entities were extracted by the following process:
- Links in the text of a Wikipedia page were annotated as entities and classified according to the Wikidata classification of the link target.
- Subsequent mentions of either an entities name or the cover text of the link on a Wikipedia page were also classified accordingly.
All entities in the graph are thus disambiguated and linked to Wikidata as a knowledge base. Nodes are not labelled with the names of the entity, but with a Wikidata ID. The graph also includes set-internal edges (e.g. between two persons or between two locations). For a brief overview of the data format, please refer to the included file metaData.txt. We also include a version of the data in tab-separated edge and node lists that include Wikidata entity identifiers, Wikidata labels and the full sentence information. If you require a representation of the data in a data base, please refer to the code linked below, which can be used for importing the graph in a MongoDB.
Download in LOAD graph format:
[zip] Download LOAD graph annotated with Wikidata and Heideltime (6.7 GB)
[zip] Download corresponding sentence content as a zip file (2.4 GB)
Download as edge / node lists (tab separated):
[zip] Download LOAD graph as edge list, including node labels and sentences (6.4 GB)
US Civil War Wikipedia LOAD graph (Wikidata + Heideltime)
In addition to the large, comprehensive LOAD graphs, we also provide a smaller graph that can be used on systems with less resources or for testing purposes. This version of the LOAD graph was constructed from a subset of the English Wikipedia. Specifically, we included only pages from the English Wikipedia (dump of 2016-05-01) that are located in the subtree of the category American Civil War at a depth of at most 3. In addition to the LOAD data itself, we included the text of both sentences and articles as JSON MongoDB exports that are formatted to work directly with the LOAD network (i.e. for sentence and page prediction tasks). In all other respects, the construction of this graph is identical to the large Wikidata + Heideltime version.
Download in LOAD graph format:
[zip] Download US Civil War LOAD graph annotated with Wikidata and Heideltime (63 MB)
Download as edge / node lists (tab separated):
[zip] Download LOAD graph as edge list, including node labels and sentences (33 MB)
Implementation & Code
To allow the creation of LOAD networks from any annotated source of
text, we provide our implementation of the LOAD generation algorithm.
Additionaly, we also include a set of tools that can be used to transfer
the internally used graph representation to an edge list format in a
MongoDB (the code can easily be adapted to write an edge list to a file
or any graph database instead). A console-based query interface for the
graph is also included.
The LOAD generation code is designed to
be able to use the output of any named entity annotation tool as input.
To this end, input data should be stored in a MongoDB from which the
program can access the documents. The required data includes
- A collection of sentences. This should include the sentence, a consecutive numbering of sentences of each page as the page ID for each sentence.
- A collection of annotations.These should be of type person, location, organization and date. Each annotation should have as an attribute the sentence and page to which it belongs as well as begin and end offsets for the sentence.
Implementation was done in Java (JVM version 7 or higher required) and uses the Java Snowball implementation of the porter stemmer, the Java mongoDB driver and the trove library. For additional information, please refer to the enclosed readme.txt file.
[zip] Download Java implementation, version 1.01 (3.4 MB)
Please
note that this is a fully working yet preliminary version of the code
that is kept simple but requires some basic knowledge of Java. A GitHub
repository for the code is in the process of being set up and thus
forthcoming. Support for further databases and applications are likely
going to be added in the future. If you would like to be notified once
this is live, or if you have any questions, please get in touch.
R Implementation
To allow the more versatile and interactive creation of LOAD networks from within the R programming framework, an R script version of the code was implemented in a software project by Katja Hauser. Unlike the Java version, it is not parallelized and scales much worse on large document collections, but is easier to use and adapt, and can be run on arbitrary documents as input (that is, it does not require entity annotation ahead of time). To create annotations, the script can either tie directly into entity annotation functionality in R, or be fed with a custom gazetteer for entity recognition. For further information, refer to the enclosed README.txt file.
[zip] Download R implementation, version 1.0 (6 MB)
Please note that this code was developed during a student project and is not actively maintained. As of January 2021, it is still fully functional, but future changes to R package dependencies may cause issues. If this does happen, please get in touch to let us know.
Legacy resources (original publication data)
For the sake of comparability, we also provide the English Wikipedia
LOAD graph that was used in the original publication (annotated with
Stanford NER and Heideltime). We do not recommend that you download this
version for any other purpose, as the new LOAD graphs (linked above)
are cleaner and more comprehensive.
[tar.gz] Download Wikipedia LOAD graph (Wikipedia dump of June 2015) (12.7 GB)
Query Interface
To facilitate browsing in the original LOAD graph, we provide an
executable version of a console-based query interface written in Java.
For working with the new versions of the LOAD graph, we recommend that
you use the updated code linked above, which also contains a query
interface with improved functionality. Please note that you need a lot
of memory to run the program, so using a machine with less than 128GB
physical memory is likely not going to work. To run the program, simply
download the graph and extract it to any folder. Then download the jar
file and run it by executing
java -Xms150g -Xmx150g -jar loadQI.jar <path to graph folder>
where
<path to graph folder> is the path to the directory that contains
the graph. Using relative paths may not work depending on your JVM, we
therefore recommend using the absolute path. Instructions on using the
program will be displayed after it launches. Note that reading the graph
into memory takes approximately 20 minutes. Java 7 or higher is
required to run the program.
[jar] Download Java Query Interface executable (170 KB)
Evaluation data
We also provide the evaluation data of hand-annotated historic events
and dates of death that was used in the publication. If you use the
data, please consider citing us. The data is stored in plain,
tab-separated csv files.
[zip] Download evaluation data (63 KB)
Publications & References
The paper that originally describes the model was presented at SIGIR '16. For your convenience, we also provide a pre-print here. If you use either the method or the data, please consider citing us as:
- Andreas Spitz and Michael Gertz.
Terms over LOAD: Leveraging Named Entities for Cross-Document Extraction and Summarization of Events.
In: Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, (SIGIR '16), Pisa, Italy, July 17-21. 2016, 503–512
[pdf] [acm] [bibtex] [slides]
- Andreas Spitz, Satya Almasian, and Michael Gertz.
EVELIN: Exploration of Event and Entity Links in Implicit Networks.
In: Proceedings of the 26th International Conference on World Wide Web (WWW '17) Companion, Perth, Australia, April 3-7. 2017, 273–277
[pdf] [acm] [bibtex] [poster] [demo]